
Jsbandpartners
Add a reviewOverview
-
Sectors Information and Technology
-
Posted Jobs 0
-
Viewed 36

Company Description
Breaking down The DeepSeek-R1 Training Process-no PhD Required

DeepSeek simply made a breakthrough: you can train a design to match OpenAI o1-level thinking using pure support knowing (RL) without utilizing identified information (DeepSeek-R1-Zero). But RL alone isn’t perfect – it can lead to difficulties like bad readability. A mix of methods in a multi-stage training repairs these (DeepSeek-R1).

—

The launch of GPT-4 permanently altered the AI market. But today, it feels like an iPhone 4 compared to the next wave of thinking models (e.g. OpenAI o1).
These “reasoning models” present a chain-of-thought (CoT) thinking phase before generating a response at reasoning time, which in turn enhances their thinking performance.
While OpenAI kept their methods under covers, DeepSeek is taking the opposite method – sharing their progress honestly and making appreciation for remaining true to the open-source mission. Or as Marc said it finest:
Deepseek R1 is one of the most amazing and excellent breakthroughs I’ve ever seen – and as open source, an extensive gift to the world. This open-source reasoning model is as excellent as OpenAI’s o1 in tasks like math, coding, and rational thinking, which is a substantial win for the open-source community … and the world (Marc, your words not ours!)
As someone who invests a lot of time working with LLMs and guiding others on how to use them, I decided to take a more detailed look at the DeepSeek-R1 training process. Using their paper as my guide, I pieced everything together and simplified into something anybody can follow-no AI PhD required. Hopefully you’ll discover it beneficial!
Now, let’s start with the basics.
A fast guide
To much better comprehend the backbone of DeepSeek-R1, let’s cover the fundamentals:
Reinforcement Learning (RL): A design learns by getting rewards or penalties based on its actions, enhancing through experimentation. In the context of LLMs, this can involve conventional RL methods like policy optimization (e.g., Proximal Policy Optimization, PPO), value-based methods (e.g., Q-learning), or hybrid strategies (e.g., actor-critic techniques). Example: When training on a prompt like “2 + 2 =”, the model gets a reward of +1 for outputting “4” and a penalty of -1 for any other response. In modern-day LLMs, benefits are often identified by human-labeled feedback (RLHF) or as we’ll soon discover, with automated scoring techniques like GRPO.
Supervised fine-tuning (SFT): A base design is re-trained using identified data to carry out much better on a particular task. Example: Fine-tune an LLM using a labeled dataset of consumer assistance questions and responses to make it more precise in managing common questions. Great to utilize if you have an abundance of labeled information.
Cold start data: A minimally identified dataset used to assist the model get a basic understanding of the job. * Example: Fine-tune a chatbot with a basic dataset of FAQ pairs scraped from a site to establish a fundamental understanding. Useful when you do not have a great deal of identified information.
Multi-stage training: A model is trained in phases, each focusing on a particular improvement, such as precision or positioning. Example: Train a model on general text information, then fine-tune it with support knowing on user feedback to improve its conversational capabilities.
Rejection tasting: A technique where a model generates outputs, however only the ones that fulfill particular criteria, such as quality or relevance, are selected for more use. Example: After a RL procedure, a model creates a number of reactions, however only keeps those that are beneficial for retraining the design.
First design: DeepSeek-R1-Zero
The team at DeepSeek wished to show whether it’s possible to train an effective reasoning design utilizing pure-reinforcement learning (RL). This type of “pure” reinforcement learning works without identified data.
Skipping labeled information? Appears like a strong relocation for RL worldwide of LLMs.
I have actually learned that pure-RL is slower upfront (trial and error takes some time) – but iteliminates the costly, time-intensive labeling bottleneck. In the long run, it’ll be much faster, scalable, and way more efficient for building thinking designs. Mostly, because they learn by themselves.
DeepSeek did a successful run of a pure-RL training – matching OpenAI o1’s efficiency.

Calling this a ‘big achievement” seems like an understatement-it’s the very first time anyone’s made this work. However, perhaps OpenAI did it initially with o1, but we’ll never understand, will we?
The biggest question on my mind was: ‘How did they make it work?’
Let’s cover what I found out.
Using the GRPO RL structure
Traditionally, RL for training LLMs has been most successful when integrated with identified data (e.g the PPO RL Framework). This RL method utilizes a critic design that resembles an “LLM coach”, providing feedback on each transfer to help the design improve. It evaluates the LLM’s actions against identified data, evaluating how most likely the model is to be successful (worth function) and directing the model’s total method.
The obstacle?
This technique is restricted by the identified information it utilizes to assess choices. If the labeled information is insufficient, prejudiced, or does not cover the complete series of jobs, the critic can only supply feedback within those restraints – and it won’t generalize well.
Enter, GRPO!
The authors used the Group Relative Policy Optimization (GRPO) RL structure (developed by the very same group, wild!) which removes the critic model.

With GRPO, you skip the ‘coach’- and the LLM relocations are scored over multiple rounds by using predefined guidelines like coherence and/or fluency. These models learn by comparing these scores to the group’s average.
But wait, how did they understand if these guidelines are the right rules?
In this approach, the guidelines aren’t perfect-they’re simply a best guess at what “great” looks like. These rules are developed to catch patterns that generally make sense, like:
– Does the answer make sense? (Coherence).
– Is it in the right format? (Completeness).
– Does it match the basic style we expect? (Fluency).
For instance, for the DeepSeek-R1-Zero model, for mathematical tasks, the design could be rewarded for producing outputs that adhered to mathematical concepts or logical consistency, even without understanding the specific answer.
It makes good sense. and it works!
The DeepSeek-R1-Zero model had piece de resistance on reasoning benchmarks. Plus it had a 86.7% of pass@1 rating on AIME 2024 (a prominent mathematics competitors for high school students), matching the efficiency of OpenAI-o1-0912.
While this looks like the biggest advancement from this paper, the R1-Zero design didn’t come with a few challenges: bad readability, and language mixing.
Second design: DeepSeek-R1
Poor readability and language mixing is something you ‘d get out of utilizing pure-RL, without the structure or formatting provided by labeled information.
Now, with this paper, we can see that multi-stage training can reduce these challenges. In the case of training the DeepSeek-R1 model, a lot of training approaches were used:
Here’s a quick description of each training stage and what it was done:
Step 1: They fine-tuned a base design (DeepSeek-V3-Base) with thousands of cold-start information indicate lay a strong structure. FYI, thousands of cold-start data points is a tiny fraction compared to the millions or perhaps billions of labeled information points usually needed for supervised knowing at scale.
Step 2: Applied pure RL (similar to R1-Zero) to boost thinking skills.
Step 3: Near RL convergence, they utilized rejection sampling where the design created it’s own identified data (artificial information) by picking the very best examples from the last effective RL run. Those rumors you’ve heard about OpenAI using smaller sized model to produce synthetic data for the O1 design? This is generally it.
Step 4: The new artificial information was merged with supervised information from DeepSeek-V3-Base in domains like writing, factual QA, and self-cognition. This step made sure the model could discover from both premium outputs and varied domain-specific understanding.
Step 5: After fine-tuning with the brand-new information, the design goes through a last RL process throughout varied prompts and scenarios.
This seems like hacking – so why does DeepSeek-R1 use a multi-stage procedure?
Because each step develops on the last.
For instance (i) the cold start information lays a structured foundation fixing problems like bad readability, (ii) pure-RL establishes thinking almost on auto-pilot (iii) rejection tasting + SFT works with top-tier training data that improves accuracy, and (iv) another last RL phase guarantees additional level of generalization.
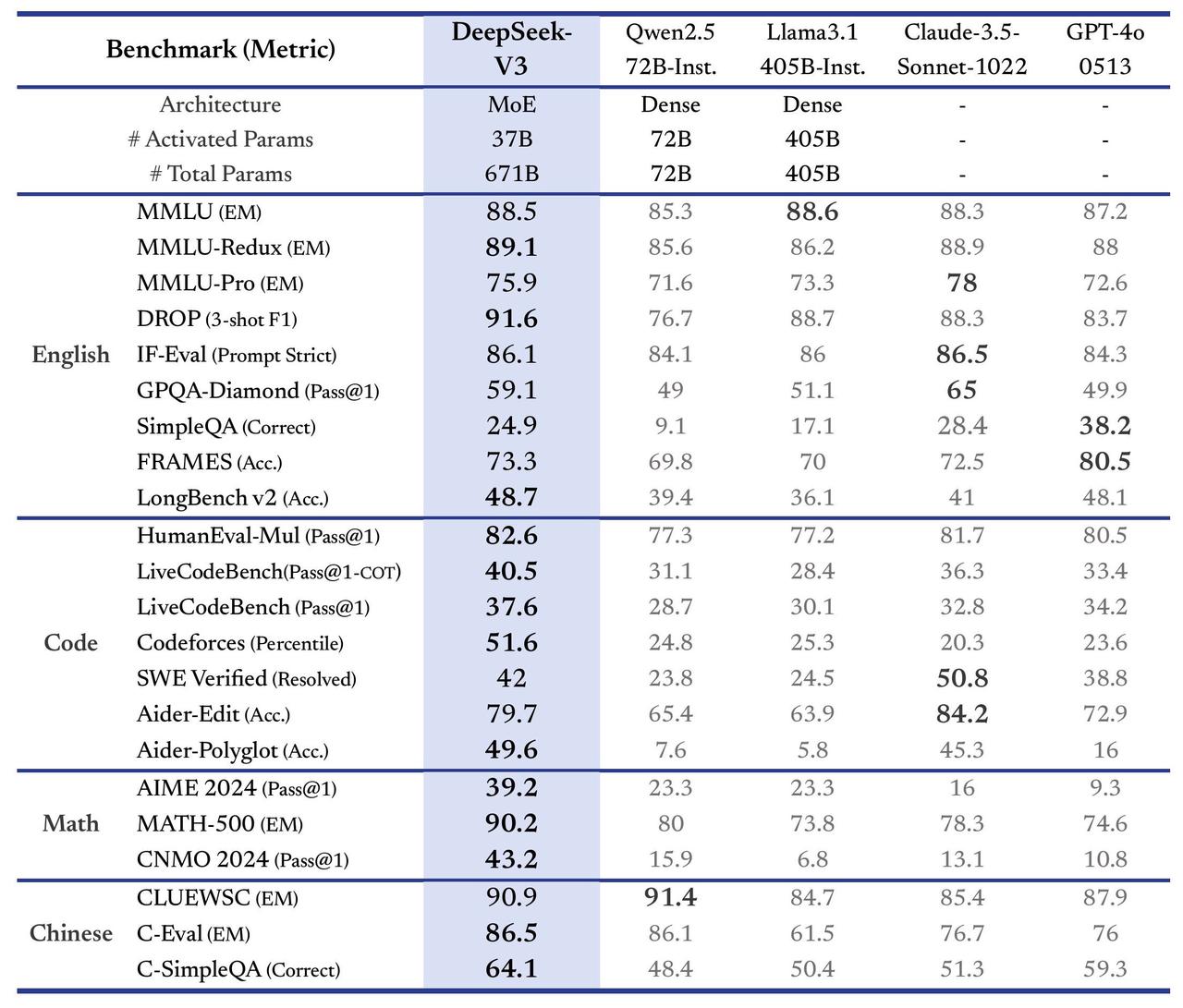
With all these extra actions in the training procedure, the DeepSeek-R1 model accomplishes high ratings throughout all standards noticeable listed below:
CoT at inference time depends on RL
To effectively utilize chain-of-thought at inference time, these reasoning designs should be trained with methods like support knowing that motivate detailed thinking throughout training. It’s a two-way street: for the model to achieve top-tier thinking, it needs to utilize CoT at inference time. And to enable CoT at inference, the design must be trained with RL approaches.
If we have this in mind, I wonder why OpenAI didn’t reveal their training methods-especially because the multi-stage process behind the o1 design appears easy to reverse engineer.
It’s clear they used RL, generated synthetic data from the RL checkpoint, and used some supervised training to improve readability. So, what did they truly attain by slowing down the competitors (R1) by simply 2-3 months?
I think time will tell.
How to utilize DeepSeek-R1
To use DeepSeek-R1 you can check it out on their complimentary platform, or get an API secret and use it in your code or by means of AI advancement platforms like Vellum. Fireworks AI also uses a reasoning endpoint for this model.
The DeepSeek hosted model, costs simply $0.55 per million input tokens and $2.19 per million output tokens – making it about 27 times cheaper for inputs and almost 27.4 times more affordable for outputs than OpenAI’s o1 design.
This API variation supports a maximum context length of 64K, however doesn’t support function calling and JSON outputs. However, contrary to OpenAI’s o1 outputs, you can retrieve both the “thinking” and the real response. It’s also extremely sluggish, however nobody cares about that with these reasoning models, since they unlock new possibilities where immediate responses aren’t the concern.
Also, this version does not support lots of other specifications like: temperature 、 top_p 、 presence_penalty 、 frequency_penalty 、 logprobs 、 top_logprobs, making them a bit harder to be used in production.
API example with DeepSeek-R1
The following Python code shows how to use the R1 design and gain access to both the CoT procedure and the last answer:
I ‘d recommend you play with it a bit, it’s rather interesting to see it ‘think’
Small models can be powerful too
The authors likewise reveal the thinking patterns of larger models can be distilled into smaller designs, resulting in better efficiency.
Using Qwen2.5-32B (Qwen, 2024b) as the base design, direct distillation from DeepSeek-R1 outshines applying simply RL on it. This demonstrates that the thinking patterns found by bigger base models are crucial for improving reasoning abilities for smaller models. Model distillation is something that is becoming rather an intriguing method, watching fine-tuning at a big scale.
The outcomes are rather effective too– A distilled 14B model outperforms modern open-source QwQ-32B-Preview by a large margin, and the distilled 32B and 70B designs set a brand-new record on the reasoning criteria among thick designs:
Here’s my take: DeepSeek simply showed that you can significantly enhance LLM reasoning with pure RL, no labeled data required. Even much better, they integrated post-training methods to repair issues and take efficiency to the next level.
Expect a flood of models like R1 and O1 in the coming weeks-not months.
We believed model scaling struck a wall, but this method is unlocking new possibilities, meaning faster progress. To put it in viewpoint, OpenAI took 6 months from GPT-3.5 to GPT-4.

